 Der optimale Weg, Remote Viewing zu lernen? Eine Frage, die sicherlich nicht in einem einzigen Artikel hinreichend beantwortet werden kann. Schließlich füllt diese Thematik inzwischen große Teile von Büchern aus der Fachliteratur. Allerdings wäre Remote Viewing nicht Remote Viewing, wenn man nicht auch mal aus Neugier eine Session auf diese Frage machen könnte. Und das haben wir natürlich getan! 🙂
Der optimale Weg, Remote Viewing zu lernen? Eine Frage, die sicherlich nicht in einem einzigen Artikel hinreichend beantwortet werden kann. Schließlich füllt diese Thematik inzwischen große Teile von Büchern aus der Fachliteratur. Allerdings wäre Remote Viewing nicht Remote Viewing, wenn man nicht auch mal aus Neugier eine Session auf diese Frage machen könnte. Und das haben wir natürlich getan! 🙂
Kategorie: Optima
Protokoll: CRV (mit Monitor)
Koordinaten: 0218 9512 4785 3621
Anzahl der Viewer: 1
Anzahl der Sessions: 1
Datum: 19.04.2013
Uhrzeit: 22.19h – 22.57h
Dauer: 38 Minuten
Seiten: 8
Die Targetformulierung lautete folgendermaßen und wurde mit einer vierfachen Möglichkeitenvorgabe (M) ergänzt:
„Beschreibe den optimalen Weg, Remote Viewing zu erlernen!“
M1 = Permanent lernen nach Vorgaben
M2 = Etwas völlig anderes
M3 = Lernen unnötig, jeder kann es
M4 = Sich selbst hineinfinden
Diese Session sollte den optimalen Ablaufweg beschreiben, und zusätzlich die treffendste der vier vorgegebenen Möglichkeiten mittels kodierter, spontaner Bemaßung aufzeigen. Die Daten der Stufen 1-3 erinnerten an die typischen Eindrücke, wenn Abläufe mit Bewusstseinskomponenten beschrieben werden. Solche Eindrücke nimmt man oft als Fluss von undefinierten Strukturen oder „Paketen“ in eine bestimmte Richtung wahr.
Konkreter wird es typischerweise ab Stufe 4. Dort zeigten sich ITs wie „im Kreis drumherum bewegen“ und „darauf zulaufen“. Wir nahme nuns dann in Stufe 6 sogleich den Begriff „zulaufen“ vor, und untersuchten ihn. Es stellte sich wie ein Wirbel aus energetischen „Blasen“ dar, die sich wie ein Wasserwirbel über einem Abfluss immer schneller drehten, bis sie schließlich nach unten gesogen werden:
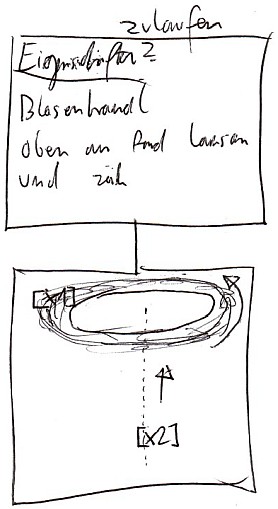
Vom Gefühl her war es so, als würde man diesen Wirbel erstmal umkreisen, um diesen aufmerksam und interessiert beobachten, bevor man sich in dessen Sog begibt. Ich skizzierte die Wahrnehmung, und mein Monitor ließ mich Markierungen auf darauf machen, einmal auf den Rand des Wirbels mit [x1], und auf den Sog mit [x2]. Diese beiden Bestandteile ließ er mich auf der nachfolgenden Seite per Timeline untersuchen. Dort sollte ich die wesentlichen ITs herausschreiben und zuordnen:
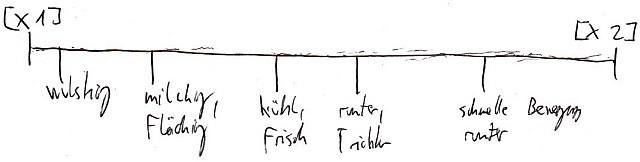
Von [X1] ausgehend waren die Eigenschaften eher zäh, wulstig und unbeweglich. Bewegte man sich jedoch weiter auf den Bereich [X2] zu, wurden sie zunehmend flüssiger, durchlässiger, „frischer“ und schneller. Deutlich spürbar war eine Beschleunigung der Bewegung, je tiefer es in den „Trichter“ des Sogs ging.
Nun ließ mich mein Monitor ein tabellarisches Mapping auf den gesamten Vorgang unter dem Gesichtspunkt „Fördernde Tätigkeitent“ erstellen. Dieses Mapping stellte sich so dar:
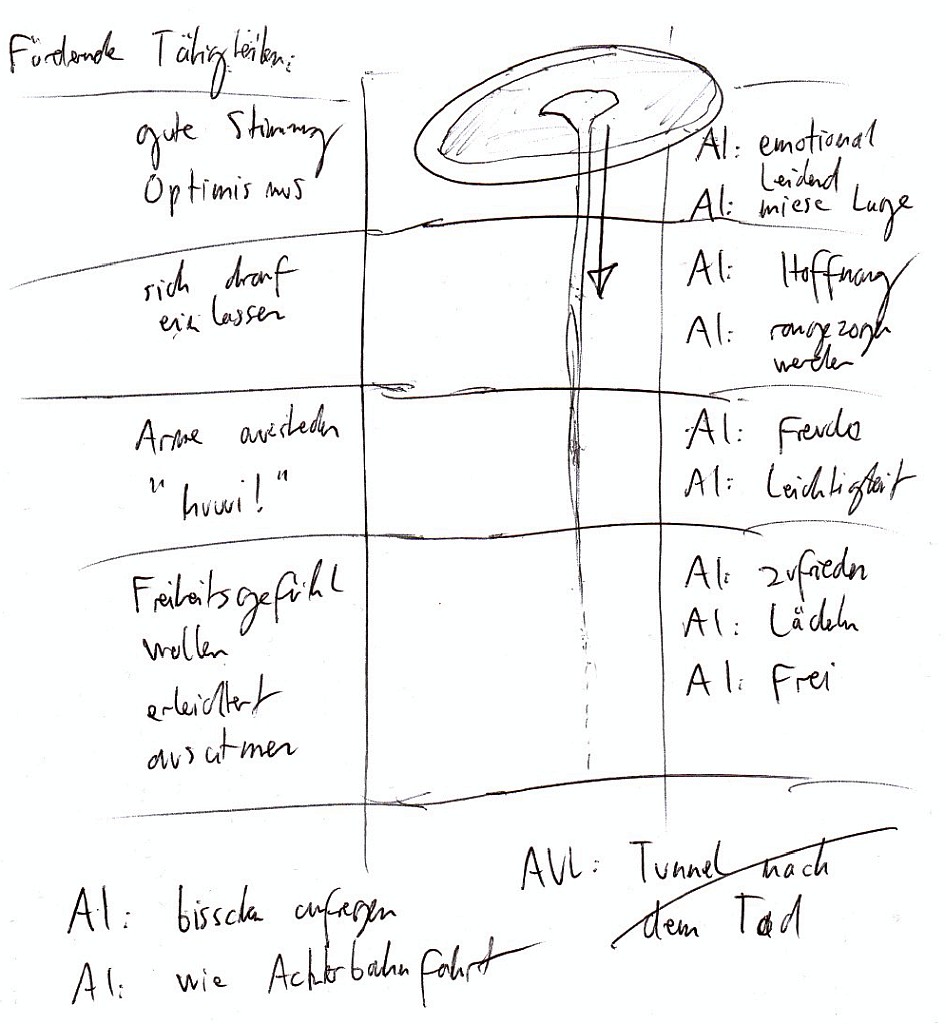
In der linken Spalte sollte die für den jeweiligen Schritt förderlichste Tätigkeit ermittelt werden, während die rechte Spalte für die eigenen emotionalen Eindrücke (AIs) der Abschnitte diente. Die Mitte diente als linearer Verlaufsmesser anhand einer detaillierteren Skizze des Wirbelablaufs.
Im ersten Schritt, dem Stadium des wulstigen Randes um den Wirbel herum kamen „gute Stimmung“ und „Optimismus“ als förderliche Tätigkeiten. Die AIs in diesem Bereich waren noch „emotional leidend“ und „miese Lage“ (oder anders ausgedrückt, auf das Target bezogen: „Ahnungslos im Regen stehen“).
Der zweite Schritt war das eigentliche aufgesogen werden in den Wirbel. Hier kam als Tätigkeit „sich darauf einlassen“ und als AIs „Hoffnung“ und „rangezogen werden“. Vom Gefühl her könnte man es wie eine anfahrende Achterbahn vergleichen, bevor es richtig rasant losgeht.
Den dritten Schritt könnte man als „mitten in der Fahrt“ bezeichnen. Die Sache ist sozusagen richtig in Fahrt gekommen. Als förderliche Tätigkeit war hier nur noch metaphorisch „Arme ausstrecken“ und „huuui!“ zu beschreiben, was man als „100% mitmachen“ und „mitreißen lassen“ übersetzen könnte. Man war jetzt voll in der Sache involviert.
Der vierte und letzte Schritt äußerte sich schließlich als ein auslaufen oder ausdünnen des Wirbelsogs. Die Sache war inzwischen wie ein Selbstläufer, und entsprechend kamen die Tätigkeiten „Freiheitsgefühl wollen“ und „erleichtert ausatmen“ fast wie von selbst. Meine dazu aufkommenden AIs lauteten „zufrieden“, „lächeln“, und „frei“. Natürlich könnte man sich dort noch aus irgendwelchen Gründen willentlich blockieren (quasi die Notbremse der Achterbahn ziehen), aber es erscheint nicht sinnvoll, da der Prozess bereits in Gang gesetzt und durchlebt wurde.
Meine finalen AIs dort waren entsprechend „ein bisschen aufregend“ und „wie Achterbahnfahrt“. Das AUL „Tunnel nach dem Tod“ konnte ich ob der Symbolik natürlich nicht für mich behalten, aber so aufregend war es dann sicherlich doch nicht (was nicht heißt, dass es kein faszinierender Ablauf war). Hier läßt sich auf jeden Fall schon ein optimaler Ablaufplan für das Lernen von Remote Viewing (und sicherlich aller anderen zu lernenden Dinge) ablesen. Lernen in seiner natürlichen Form eben (dass in unserem Schulsystem oft der dazugehörige „Sog“ fehlt, ist ein ganz anderes Thema… ;)).
Kommen wir zum Schluss aber noch zu der spontanen Bemaßung der im Target enthaltenen Möglichkeitenvorgabe. Hier nochmal die (für den Viewer unsichtbare) Kodierung:
M1 = Permanent lernen nach Vorgaben
M2 = Etwas völlig anderes
M3 = Lernen unnötig, jeder kann es
M4 = Sich selbst hineinfinden
Und hier das Resultat:
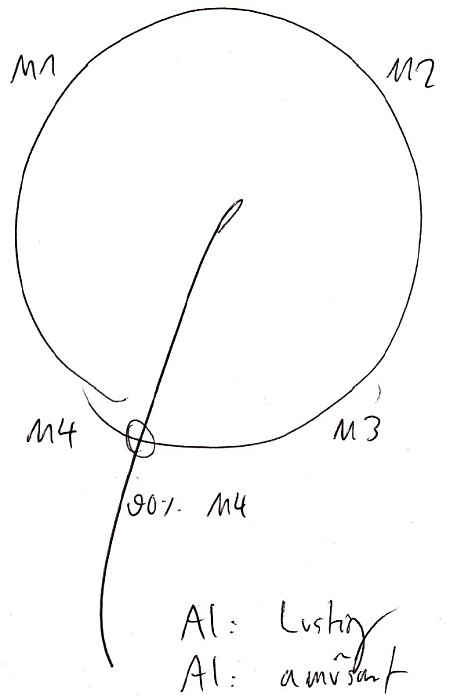
Wie eigentlich zu erwarten, traf hier zu geschätzten 90% M4 („sich selbst hineinfinden“) zu. Es ist ein interaktiver, größtenteils autodidaktischer Lernprozess. Aber auch eine kleine Tendenz zu M3 („lernen unnötig, jeder kann es“) war erkennbar, was sich meiner Meinung nach auf die grundlegende PSI-Fähigkeit an sich bezieht, nicht auf den formalen Prozess des Remote Viewings (Protokollablauf). Einfinden muss man sich also in die Abläufe des Protokolls, das AUL-Management, das Finden des eigenen Timings etc… Deshalb ist Starthilfe durch eine solide Remote Viewing-Ausbildung sehr hilfreich (wenn auch kein unbedingtes Muss), um sich nicht zu lange am „wulstigen Rand“ aufhalten zu müssen, sondern schnellmöglch in Fahrt zu kommen. Denn dadurch fließt die Energie des Verstehens, und diese motiviert einen, bei der Sache zu bleiben, und den individuellen Prozess immer weiter zu optimieren.
Fazit: Diese interessante Session deutet wie gesagt gut darauf, wie das Lernen an sich funktioniert, und wie man dessen Effektivität optimieren kann. Das Auswändiglernen von toten Informationen, mit denen man in der Praxis nichts tut, läßt jeden Lernvorgang irgendwann stagnieren, weil die Bewegung immer zäher wird, und schließlich stoppt. Auch wenn man sich jahrelang zwingt, in diesem zähen „Wulst“ weiterzurühren (siehe wieder Schulsystem), fließt keine Energie zurück, und es endet leer bzw. frustrierend (z.B. damit, dass das Meiste davon wieder vergessen wird, weil es einfach unnütze, tote Daten sind, die nicht in der Praxis des Lebens und Erlebens angewendet werden). Vielleicht wird es endlich Zeit für einige Optimierungen.. 😉
Schreibe einen Kommentar